Statsmodels for time series data
A brief introduction to statsmodel which helps in dealing with time-series data.
In python, a very widely used library named statsmodel is used when dealing with time-series data. It is based on the statistical programming language R. This module helps in analyzing data, perform statistical functions and also create statistical models. It also has functions to plot.
So let’s dive into it!
→Installation
The statsmodel is already included in the python environment file. In case a different environment like Anaconda is used then install by using the command below:
conda install statsmodels
→ Importing packages
The basic packages like NumPy and pandas to help deal with data are imported along with matplotlib to help with plottings.
>>> import pandas as pd
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> %matplotlib inlineThen the statsmodel is also imported.
>>> import statsmodels.api as sm→ Obtain data
The statsmodels has a provision to obtain the dataset. There are various datasets as shown below:

The one that will be used is the macrodata since it is a time-series data. Using the load_pandas() method, the data will be loaded.
>>> data = sm.datasets.macrodata.load_pandas().data
>>> data.head()
>>> data.tail()
To understand what the column headings mean, we can print the details using the NOTE attribute.
>>> print(sm.datasets.macrodata.NOTE)
::
Number of Observations - 203 Number of Variables - 14 Variable name definitions:: year - 1959q1 - 2009q3
quarter - 1-4
realgdp - Real gross domestic product (Bil. of chained 2005 US$,
seasonally adjusted annual rate)
realcons - Real personal consumption expenditures (Bil. of chained
2005 US$, seasonally adjusted annual rate)
realinv - Real gross private domestic investment (Bil. of chained
2005 US$, seasonally adjusted annual rate)
realgovt - Real federal consumption expenditures & gross investment
(Bil. of chained 2005 US$, seasonally adjusted annual rate)
realdpi - Real private disposable income (Bil. of chained 2005
US$, seasonally adjusted annual rate)
cpi - End of the quarter consumer price index for all urban
consumers: all items (1982-84 = 100, seasonally adjusted).
m1 - End of the quarter M1 nominal money stock (Seasonally
adjusted)
tbilrate - Quarterly monthly average of the monthly 3-month
treasury bill: secondary market rate
unemp - Seasonally adjusted unemployment rate (%)
pop - End of the quarter total population: all ages incl. armed
forces over seas
infl - Inflation rate (ln(cpi_{t}/cpi_{t-1}) * 400)
realint - Real interest rate (tbilrate - infl)
Now to work with time series, it is important to have the year column as the index. So accordingly it is changed by using the time series analysis (tsa) module of statsmodels. It has a method called dates_from_range where the range can be mentioned. We take the start to be 1959 year of the first quarter (Q1) and end to be 2009 of the third quarter (Q3). Using pandas an index will be created of this.
>>> idx = pd.Index(sm.tsa.datetools.dates_from_range('1959Q1','2009Q3'))Now that the index is created, we can assign it to the dataframe.
>>> data.index = idx
>>> data.head()
→ Visualization
The linear plot of the DPI is plotted to see the trend.
>>> data['realdpi'].plot()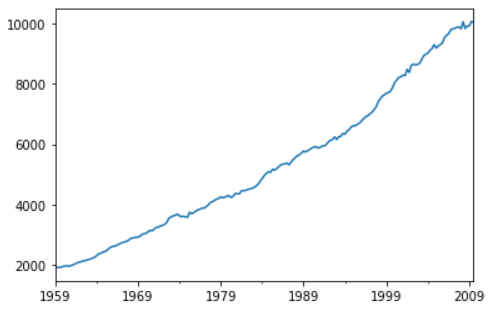
The statsmodel can be useful in getting the estimated trend. A filter is used which is called as Hodrick-Prescott filter. This filter distinguishes a time-series data into a trend and a cyclic component. When this filter is applied it returns a tuple that consists of the estimated cycle and the trend.
>>> dpi = sm.tsa.filters.hpfilter(data['realdpi'])
>>> dpi
(1959-03-31 32.611738
1959-06-30 45.961546
1959-09-30 23.190972
1959-12-31 18.550907
1960-03-31 23.077748
...
2008-09-30 -128.596455
2008-12-31 -87.557288
2009-03-31 -122.358968
2009-06-30 -11.941350
2009-09-30 -89.467814
Name: realdpi_cycle, Length: 203, dtype: float64,
1959-03-31 1854.288262
1959-06-30 1873.738454
1959-09-30 1893.209028
1959-12-31 1912.749093
1960-03-31 1932.422252
...
2008-09-30 9966.896455
2008-12-31 10007.957288
2009-03-31 10048.758968
2009-06-30 10089.441350
2009-09-30 10130.067814
Name: realdpi_trend, Length: 203, dtype: float64)Now using the tuple unpacking, the trend is extracted and then plotted.
>>> dpi_cycle,dpi_trend = sm.tsa.filters.hpfilter(data['realdpi'])
>>> data['trend'] = dpi_trend
>>> data[['realdpi','trend']].plot()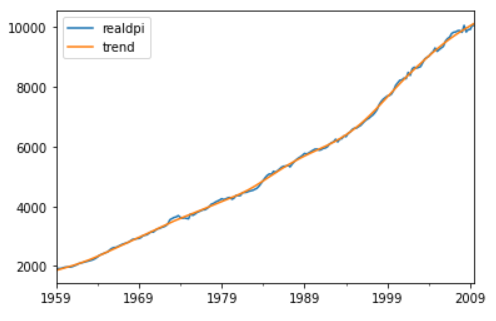
Let’s zoom in to get a better idea of the plot.
>>> data[['realdpi','trend']]['2005-01-01':].plot()
With this, you have a basic understanding of using the statsmodels library. For more detailed information, check out the official documentation below.
Refer to the notebook for code here.
Reach out to me: LinkedIn
Check out my other work: GitHub

